| .vscode | ||
| aimodel | ||
| rainfallwrangler | ||
| .gitignore | ||
| LICENSE.md | ||
| README.md | ||
| research-rainfallradar overview.drawio | ||
| research-rainfallradar overview.png | ||
{kind=link}
Rainfall Radar
A model to predict water depth data from rainfall radar information.
This is the 3rd major version of this model.
Unfortunately using this model is rather complicated and involves a large number of steps. There is no way around this. This README explains it the best I can though.
Should anything be unclear, please do open an issue.
Paper
The research in this repository has been published in a conference paper(!)
- Title: Towards AI for approximating hydrodynamic simulations as a 2D segmentation task
- Conference: Northern Lights Deep Learning Conference 2024
- Permanent Link: https://proceedings.mlr.press/v233/bryan-smith24a/bryan-smith24a.pdf
Abstract:
Traditional predictive simulations and remote sensing techniques for forecasting floods are based on fixed and spatially restricted physics-based models. These models are computationally expensive and can take many hours to run, resulting in predictions made based on outdated data. They are also spatially fixed, and unable to scale to unknown areas.
By modelling the task as an image segmentation problem, an alternative approach using artificial intelligence to approximate the parameters of a physics-based model in 2D is demonstrated, enabling rapid predictions to be made in real-time.
System Requirements
- Linux (Windows may work but is untested. You will probably have a bad day if you use Windows)
- Node.js (a recent version - i.e. v16+ - the version in the default Ubuntu repositories is too old)
- Python 3.8+
- Nvidia GPU (16GiB RAM+ is strongly recommended) + CUDA and CuDNN (see this table for which versions you need)
- Experience with the command line
- 1TiB disk space free
- Lots of time and patience
Note
The format that HAIL-CAESAR accepts data in results in a ~450GiB rainfall radar file O.o
Thankfully the format that
nimrod-data-downloaderdownloads in is only a couple of GiB in the end, and the.tfrecordfiles that the model accepts is only ~70GiB.
Overview
The process of using this model is as as illustrated:
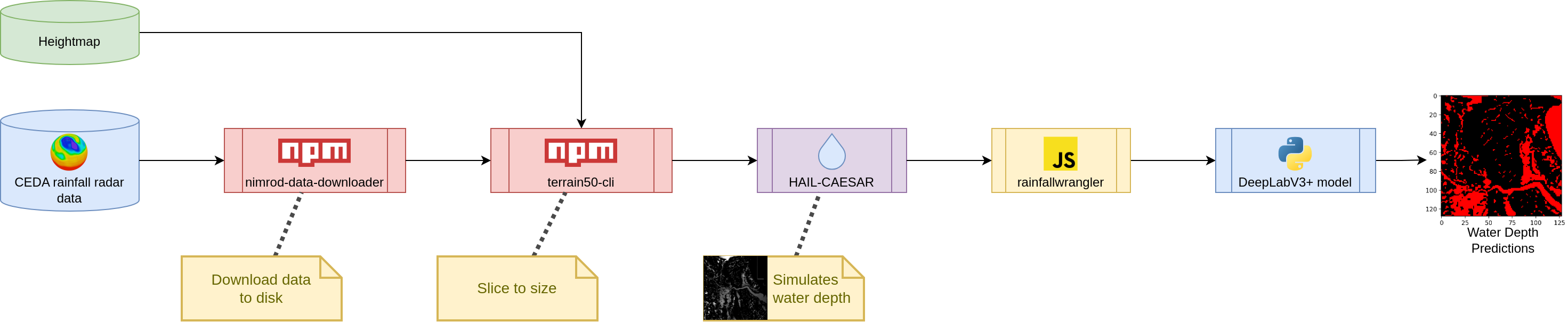
More fully:
- Apply for access to CEDA's 1km rainfall radar dataset
- Download 1km rainfall radar data (use
nimrod-data-downloader) - Obtain a heightmap (or Digital Elevation Model, as it's sometimes known) from the Ordnance Survey (can't remember the link, please PR to add this)
- Use
terrain50-clito slice the the output from steps #2 and #3 to be exactly the same size [TODO: Preprocess to extract just a single river basin from the data] - Push through HAIL-CAESAR (this fork has the ability to handle streams of .asc files rather than each time step having it's own filename)
- Use
rainfallwranglerin this repository (finally!) to convert the rainfall, heightmap, and water depth data to a .json.gz dataset, and then to a set of .tfrecord files the model can read and understand - Train a DeepLabV3+ prediction model
Only steps #6 and #7 actually use code in this repository. Steps #2 and #4 involve the use of modular npm packages.
Obtaining the data
The data in question is the Met Office's NIMROD 1km rainfall radar dataset, stored in the CEDA archive. It is updated every 24 hours, and has 1 time step every 5 minutes.
The data can be found here: https://catalogue.ceda.ac.uk/uuid/27dd6ffba67f667a18c62de5c3456350
There is an application process to obtain the data. Once complete, use the tool nimrod-data-downloader to automatically download & parse the data:
https://www.npmjs.com/package/nimrod-data-downloader
This tool was also written me, @sbrl - the primary author on the paper mentioned above.
Full documentation on this tool is available at the above link.
Heightmap: Anything will do, but I used the Ordnance Survey Terrain50 heightmap, since it is in the OS National Grid format (eww >_<), same as the aforementioned rainfall radar data.
Running the simulation
Once you have your data, ensure it is in a format that the HAIL-CAESAR model will understand. For the rainfall radar data, this is done using the radar2caesar command of nimrod-data-downloader, as mentioned above.
before running the simulation, the heightmap and rainfall radar will need cropping to match one another. For this the tool terrain50-cli was developed.
Once this is done, the next step is to run HAIL-CAESAR. Details on this can be found here:
https://github.com/sbrl/HAIL-CAESAR/
....unfortunately, due to the way HAIL-CAESAR is programmed, it reads all the rainfall radar data into memory first before running the simulation. From memory for data from 2006 to 2020 it used approximately 350GiB - 450GiB RAM.
Replacing this simulation with a better one is on the agenda for moving forwards with this research project - especially since I need to re-run a hydrological simulation anyway when attempting a tile-based approach.
Preparing to train the model
Once the simulation has run to completion, all 3 pieces are now in place to prepare to train an AI model. The AI model training process requires that data is stored in .tfrecord files for efficiency given the very large size of the dataset in question.
This is done using the rainfallwrangler tool in the eponymous directory in this repository. Full documentation on rainfallwrangler can be found in the README in that directory:
rainfallwrangler is a Node.js application to wrangle the dataset into something more appropriate for training an AI efficiently. The rainfall radar and water depth data are considered temporally to be regular time steps. Here's a diagram explaining the terminology:
NOW
│ │ │Water depth
│▼ Rainfall Radar Data ▼│[Offset] │▼
├─┬─┬─┬─┬─┬─┬─┬─┬─┬─┬─┬─┼─┬─┬─┬─┬─┼─┐
│ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │
│ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │
│ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │
│ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │
└─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┼─┴─┴─┴─┴─┴─┘
│
◄────────── Timesteps ─────────────►
This is also the point at which the compression of the rainfall history the DeepLabV3+ model sees is done - i.e. compressing multiple timesteps with max() to save VRAM.
Note to self: 150.12 hashes/sec on i7-4770 4c8t, ???.?? hashes/sec on Viper compute
After double checking, rainfallwrangler does NOT mess with the ordering of the data.
Training the model
After all of the above steps are completed, a model can now be trained.
The current state of the art (that was presented in the above paper!) is based on DeepLabV3+. A note of caution: this repository contains some older models, so it can be easy to mix them up. Hence this documentation :-)
This model is located in the file aimodel/src/deeplabv3_plus_test_rainfall.py, and is controlled via a system of environment variables. Before using it, you must first install any dependencies you're missing:
pip3 install --user -r aimodel/requirements.txt
The model should work with any recent version of Tensorflow. See the version table if you are having trouble with CUDA and/or CuDNN.
With requirements installed, we can train a model. The general form this is done is like so:
cd aimodel;
[ENVIRONMENT_VARIABLES_HERE] src/deeplabv3_plus_test_rainfall.py
This model has mainly been tested and trained on the University of Hull's Viper HPC, which runs Slurm. As such, a Slurm job file is available in aimodel/slurm-TEST-deeplabv3p-rainfall.job, which wraps the aforementioned script.
The following environment variables are supported:
| Environment Variable | Meaning |
|---|---|
| IMAGE_SIZE=128 | Optional. Sets the size of the 'images' that the DeepLabV3+ model will work with. |
| BATCH_SIZE=64 | Optional. Sets the batch size to train the model with. |
| DIR_RAINFALLWATER | The path to the directory the .tfrecord files containing the rainfall radar / water depth data. |
| PATH_HEIGHTMAP | The path to the heightmap jsonl file to read in. |
| PATH_COLOURMAP | The path to the colourmap for predictive purposes. |
| DIR_OUTPUT | The directory to write output files to. Automatically calculated in the Slurm job files unless manually set. See POSTFIX to alter DIR_OUTPUT without disrupting the automatic calculation. If you are calling slurm-TEST-deeplabv3p-rainfall.job directly then you MUST set this environment variable manually. |
| PARALLEL_READS | Multiplier for the number of files to read in parallel. 1 = number of CPU cores available. Very useful on high-read-latency systems (e.g. HPC like Viper) to avoid starving the GPU of data. WILL MANGLE THE ORDERING OF DATA. Set to 0 to disable and read data sequentially. WILL ONLY NOT MANGLE DATA IF PREDICT_AS_ONE IS SET. Defaults to 1.5. |
| STEPS_PER_EPOCH | The number of steps to consider an epoch. Defaults to None, which means use the entire dataset. |
| NO_REMOVE_ISOLATED_PIXELS | Set to any value to avoid the engine from removing isolated pixels - that is, water pixels with no other surrounding pixels, either side to side to diagonally. |
| EPOCHS=50 | The number of epochs to train for. |
| LOSS="cross-entropy" | The loss function to use. Default: cross-entropy (possible values: cross-entropy, cross-entropy-dice). |
| DICE_LOG_COSH | When in cross-entropy-dice mode, in addition do loss = cel + log(cosh(dice_loss)) instead of just loss = cel + dice_loss. Default: unset |
| WATER_THRESHOLD=0.1 | The threshold to cut water off at when training, in metres. Default: 0.1 |
| PATH_CHECKPOINT | The path to a checkpoint to load. If specified, a model will be loaded instead of being trained. |
| LEARNING_RATE=0.001 | The learning rate to use. Default: 0.001. |
| UPSAMPLE=2 | How much to upsample by at the beginning of the model. A value of disables upscaling. Default: 2. |
| STEPS_PER_EXECUTION=1 | How many steps to perform before surfacing from the GPU to e.g. do callbacks. Default: 1. |
| RANDSEED | The random seed to use when shuffling filepaths. Default: unset, which means use a random value. |
| JIT_COMPILE | Set to any value to compile the model with XLA. Defaults to unset; set to any value to enable. |
| PREDICT_COUNT=25 | The number of items from the (SCRAMBLED) dataset to make a prediction for. |
| PREDICT_AS_ONE | [prediction only] Set to any value to avoid splitting the input dataset into training/validation and instead treat it as a single dataset. Default: False (treat it as training/validation) |
| POSTFIX | Postfix to append to the output directory name (primarily auto calculated if DIR_OUTPUT is not specified, but this allows adjustments to be made without setting DIR_OUTPUT). |
| ARGS | Optional. Any additional arguments to pass to the python program. |
Important
It is strongly advised that all filepaths do NOT contain spaces.
Making predictions: Set PATH_CHECKPOINT to point to a checkpoint file to make predictions with an existing model that you trained earlier instead of training a new one. Data is pulled from the given dataset, same as during training. The first PREDICT_COUNT items in the dataset are picked to make a prediction.
Note
The dataset pipeline is naturally non-deterministic with respect to the order in which samples are read. Ensuring the ordering of samples is not mangled is only possible when making predictions, and requires a number of environment variables to be set:
PREDICT_AS_ONE: Set to any value to disable the training / validation splitPARALLEL_READS: Set to0to reading input files sequentially.
Contributing
Contributions are very welcome - both issues and pull requests! Please mention in any pull requests that you release your work under the AGPL-3 (see below).
We acknowledge and thank the VIPER high-performance computing facility of the University of Hull and its support team, without whom this project would not have been possible.
License
All the code in this repository is released under the GNU Affero General Public License 3.0 unless otherwise specified. The full license text is included in the LICENSE.md file in this repository. GNU have a great summary of the licence which I strongly recommend reading before using this software.
[!NOTE] AGPL 3.0 was chosen for a number of reasons. The code in this repository has taken a very large amount of effort to put together, and to this end it is my greatest wish that this code and all derivatives be open-source. Open-source AI models enable the benefits thereof to be distributed and shared to all, and ensure transparency surrounding methodology, process, and limitations.
You may contact me to negotiate a different licence, but do not hold out hope.
--Starbeamrainbowlabs, aka Lydia Bryan-Smith
Primary author